
미래 포럼
제목 : UC 버클리 "딥시크 추론 능력 30달러로 재현"
미래 기술 (Technology)
작성일 : 2025-02-09 22:29
조회수 : 243
작성자 : admin
 (사진=셔터스톡)
(사진=셔터스톡)UC 버클리 연구진이 단돈 30달러(약 4만3750원)로 딥시크의 핵심 기술을 재현했다고 밝혔다. 이는 첨단 AI 모델을 보다 낮은 비용으로 구현할 가능성을 보여준다.
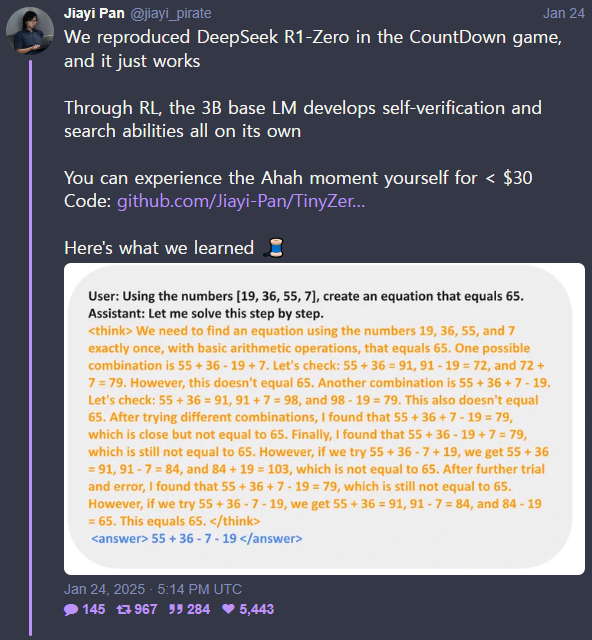
UC 버클리 연구진은 최근 소셜 미디어 니터를 통해 30달러의 비용으로 '딥시크-R1-제로(DeepSeek-R1-Zero)'의 핵심 기술을 재현한 매개변수 3B 모델을 개발했다며, 이를 깃허브에 공유했다.
R1-제로는 최근 주목받은 R1의 기반이 된 모델이다. 훈련 과정에서 지도 미세조정(SFT)을 생략, 작업을 단순화했다. 그런데도 수학 추론 벤치마크(AIME 2024)에서 'o1'과 비슷한 성능을 기록했다.
연구진은 R1-제로와 같은 성능을 가진 모델을 재현하기 위해 '카운트다운(Countdown)' 게임을 통해 강화학습(RL)을 진행했다.
카운트다운 게임은 참가자들이 주어진 6개의 숫자를 덧셈, 뺄셈, 곱셈, 나눗셈으로 목표 숫자에 가까운 결과를 만드는 것이다. 영국의 유명 게임쇼에서 시직된 것으로, 이를 통해 참가자들의 지능을 테스트하는 것이다.
작은 AI 모델이 게임을 수행하며 스스로 정답을 확인하고 찾는 능력이 발전한다는 의도다. 연구진은 모델에 프롬프트를 입력하고 결과에 따라 보상을 주는 RL 방식을 채택했다.
처음에는 모델이 무작위로 답을 제출했지만, 학습을 거치며 답을 수정하고 다시 확인하는 전략을 익히게 됐다고 밝혔다. 즉, 모델이 먼저 답을 제시한 뒤 정답 여부를 검증하고 여러 번의 반복을 거쳐 올바른 해결책을 도출하는 모습이 나타났다는 것이다.
또 연구진은 R1-제로를 재현한 모델로 다양한 크기의 매개변수를 실험했다. 처음에는 5억개의 매개변수를 가진 '큐원-2.5B(Qwen-2.5-Base)'를 사용했는데, 이 모델은 정답을 단순히 추측하고 추론을 멈춰 버렸다.
그러나 매개변수를 15억개로 확장하자, 모델이 더 높은 점수를 얻기 위해 다양한 문제 해결 전략을 스스로 학습하기 시작했다고 전했다. 30억개와 70억개의 매개변수를 사용하면 더 적은 단계로 정답에 근접해 나갔다.
매개변수가 커지며 모델 능력이 향상하는 것은 당연한 일이지만, 주목할 점은 연구진이 이 실험을 단 30달러의 비용으로 수행했다고 주장한 것이다.
(사진=니터)
물론, 이번 연구로 실제 R-1과 비슷한 성능을 가진 모델이 만들어졌다는 것은 아니다.
이 모델의 R-1급 추론 능력은 카운트다운 게임을 수행하는 능력에만 한정된다. 일반적인 추론 작업에서는 통하지 않으면, 특정 분야로 확장하려면 도메인에 맞는 RL을 수행해야 한다.
이번 연구를 리드한 지아 판 UC 버클리 박사과정은 "이 프로젝트가 떠오르는 RL 스케일링 연구의 신비를 풀고 더 쉽게 접근할 수 있도록 도움이 되기를 바란다"라고 목표를 밝혔다.
물론 V3의 개발 비용이 557만달러(약 82억원)에 불과하다는 딥시크의 주장은 여러 전문가로부터 과장이라고 지적받고 있다.
세미애널리시스는 V3 개발에 최소 5억달러가 들었을 것으로 분석했으며, 머신러닝 전문가 네이선 램버트도 5억~10억달러에 이를 것으로 추정했다.
이처럼 R1의 등장으로 인해 저비용으로 모델을 훈련하는 기술에 대한 연구가 잇따를 것으로 보인다.
앞서 지난 10일에는 UC 버클리의 연구실인 노바스카이(NovaSky)가 450달러(약 66만원)에 불과한 비용으로 고급 추론 기능을 갖춘 오픈 소스 모델 ‘스카이-T1-32B-프리뷰(Sky-T1-32B-Preview)’를 제작했다고 밝혔다.
이 모델은 기존 모델로 합성 데이터를 만들고 이를 미세조정하는 등 '복제'에 불과하다. 하지만, 딥시크도 o1을 증류한 것으로 알려지는 등 최소한의 컴퓨팅 리소스로 강력한 AI 시스템을 구축하려는 시도가 이어지고 있다.
Copyright © '인공지능 전문미디어' AI타임스 (http://www.aitimes.com)
박찬 기자 cpark@aitimes.com



